
The source for this document is maintained at https://github.com/hbz/hbz.github.com | General hbz page: hbz.github.io
Lobid development process
This section documents how we create software in the Lobid team at hbz.
GitHub
We develop our software on GitHub. We don’t publish the results of our development process on GitHub, but instead do the actual development (track issues, change code, discuss changes) in the open. Publishing our development process in this document is part of this transparent process.
GitHub Flow
We use the simple GitHub workflow: the master branch in always the version that is actually deployed to production, new features are developed in feature branches, which are merged into the master after review in pull requests. See details on the GitHub flow.
GitHub Issues
We have different Git repositories under different GitHub organisations. New repositories are created under the
hbz organisation. We use GitHub issues to keep track of requirements, new features and bugs. Bugs (i.e. defects in existing functionality) are marked with the
bug label and are prioritized over new features.
Board
For a unified view of all issues in the various repositories we use a board at https://github.com/orgs/hbz/projects/2.
The columns of our board correspond the subsequent stages of our development process, from left to right:
Backlog
-> Ready
-> Working
-> Review
-> Deploy
-> Done
Columns are set up on the project on GitHub, i.e. moving a card from
working to
review is the same as changing the setting under 'Projects' from
working to
review on the issue in GitHub. New issues need to be added to the board/project (again, either on the board, or from the issue).
Process Stages
Backlog
The backlog contains all planned issues.
Ready
An item is
ready if it’s possible to start working on it, i.e. there are no blocking dependencies and requirements are clear enough to start working. Dependencies are expressed through simple referencing of the blocking issue (e.g.
dependes on #111), see
details on referencing. Prioritized items (like
bugs) are moved to the top of the
ready column.
Working
When we start working on an issue, we move it to the
working column. Ideally, every person should only work on one issue at a time. That way the
working column provides an overview of who is currently working on what. Issues are only moved into or out of the working column by the person who is assigned. Issues in working are only reassigned by the person who is currently assigned.
We include references to the corresponding issue in the commit messages. We don’t use keywords for closing issues in the commit messages, since the resolution decision does not happen during implementation, but during review (see below).
Review
Deploy changes
When an issue is completed on the technical side, we push the corresponding commits to a feature branch that contains the corresponding issue number and additional info for convenience (using camelCaseFormatting, e.g.
111-featureDesciption). If the issue is in a different repo than the branch, we prefix the repo name, e.g.
nwbib-111-ui.
We then open a pull request for the feature branch with a summary of the changes as its title, and a link to the corresponding issue using keywords for closing issues (like Will resolve #123, this will create a link from the issue to the pull request). We leave the pull request unassigned at this point.
We then deploy the changes from the feature branch to our stage or test system by merging the feature branch on the server and restarting the system.
Functional review
To submit the changes for functional review, we now add instructions and links for testing the changed behavior on the stage or test system in the issue, assign the issue for functional review, and move it to the
review column.
If the reviewers find problems during the review, they describe the issues, providing links that show the behavior, and reassign the team member that submitted the issue for review, leaving the issue in the review column.
If everything works as expected, the reviewers post a
+1 comment on the issue, unassign the issue, and assign the corresponding pull request for code review (the pull request is linked from the issue due to the closing keywords used in the pull request).
Code review
Changes during the review process are created in additional commits, which are pushed to the feature branch. They are added to the existing pull request automatically. See details on pull requests.
At the end of the code review, the reviewer posts a
+1 comment, reassigns the pull request to its original creator, and moves the associated issue to the
deploy column (or changes the project setting on the issue using the GitHub issue UI, this will move the card into the
deploy column).
Continuous integration
We use Travis CI for continuous integration. The CI is integrated into the GitHub review process: when a pull request is opened, Travis builds the resulting merged code and provides feedback right in the pull request. For details, see
this post. The creator of the pull request should ensure the Travis build was successful. Since code reviews conclude with a
+1 comment (and not with a merge), the reviewers can give their
+1 even if the Travis build is failing.
Deploy
After the code review, the developer of the feature merges the pull request, deploys the new functionality to production, and deletes the corresponding branch. We don’t deploy to production on Friday afternoons or right before leaving for a vacation. To ensure that the master is always the deployed state, and to only close issues when they are actually deployed to production, merging the pull request should not happen using the GitHub web UI, but on the production server:
1. Log in to the server for the production system, and go to the repo you want to deploy
2. Pull the feature branch into the master, e.g.
git -c "user.name=First Last" -c "user.email=name@example.com" pull --no-ff origin 111-ui (we have a single deployment user on our server, so we have to pass our name and email to the git pull command)
3. Restart the production app: sh restart.sh service-name and test the new functionality
4. Amend the merge commit:
git commit --amend to include a reference to the resolved issue using
keywords for closing issues and instructions on how to replicate the change in production (usually a link to the production system demonstrating the new functionality), e.g.
Resolves https://github.com/hbz/nwbib/issues/239
See http://nwbib.de/search?q=Neuehrenfeld
5. Push the changes to master:
git push origin master, and delete the feature branch, e.g.
git push origin :111-ui
Done
After deployment, both the issue and the pull request are closed automatically, and their card is moved to the
done column.
Conventions
Coding Conventions
We use a custom Eclipse formatter profile to ensure consistent formatting. We use custom Eclipse compiler settings to ensure consistent coding style. The settings are checked in to the repos and require no specific setup. Code that is submitted to review should contain no warnings in Eclipse. The formatting is applied automatically through Eclipse Save Actions.
Git Conventions
Git commits should be as granular as possible. When working on a fix for issue X, we try not to add other things we notice (typos, formatting, refactorings, etc.) to the same commit. Eclipse has UI for partial staging, which is very useful to keep commits focussed.
Commit Messages
We follow the established conventions for Git commit messages: imperative mood (e.g.
Fix UI issue, not
Fixes UI issue), short lines (max 72 chars), and either just one line, or one line, a blank line, and one or more paragraphs. For details, see
these
posts.
Every commit should be related to a GitHub issue. This allows us to understand why certain changes were applied. When committing to the same repo that contains the issue, it’s enough to just mention the issue number with a prefixed
# mark, e.g.
Fix UI issue (#111). If the issue is in a different repo, we have to add the full link (in a paragraph under the summary line, see above).
We don’t use the GitHub shortcuts for closing issues from commits (like
fixes #111), since in our process, the issue is not solved by the commit, but by the reviewed change, after it’s deployed to production (see above).
Force Pushing
As a general rule, we never change public commit history, i.e. we don’t use
--force or
-f with
git push. The only exception are branches prefixed with
wip- (work in progress), which are considered private to the developer. Pull requests should always be opened for non-wip branches. Local amending and rebasing before pushing to GitHub is no problem and will not require to
--force when pushing. While we consider this general rule as directive, we condone force pushing as long as the branch has no open pull request yet
and only one person is working on this branch. In case of a force push we use --force-with-lease to ensure that we do not overwrite any remote commits. In case of an open pull request, instead of force pushing
we open a new branch from master and cherry-pick needed commits or add new code in this branch. The old branch and the existing pull request should be closed then.
Lobid micro architecture
For increased reuse, we’re trying to apply the idea of a unified macro (see above) and micro architecture to the development of new Lobid modules. For reference implementations of the Lobid micro architecture, see https://github.com/hbz/lobid-organisations (data module) and https://github.com/hbz/nwbib (application module).
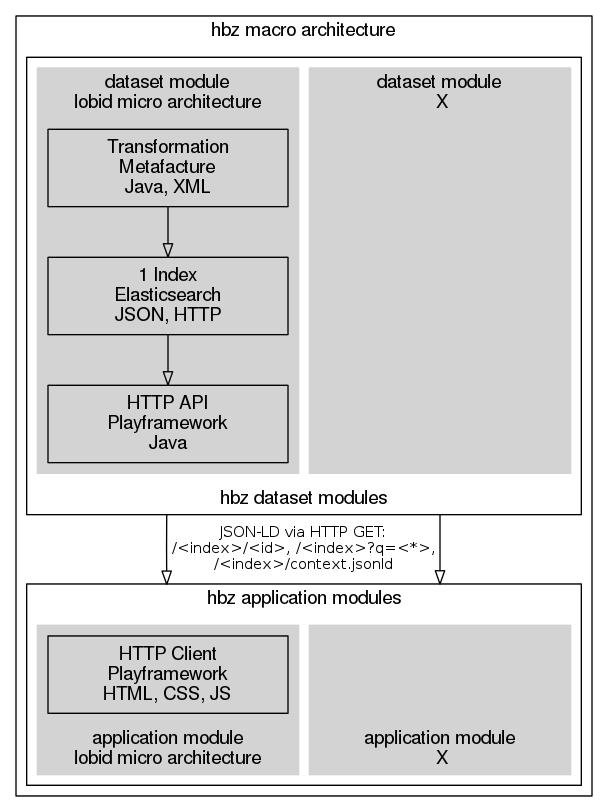
Lobid data modules
Lobid data modules are implemented with Metafacture, Elasticsearch, and the Playframework. A basic idea of the Lobid micro architecture is to provide a focused, independently deployable module that does one thing: provide 1 data set, with 1 Elasticsearch index (and thus, 1 index config file), 1 build, 1 CI config, 1 README. The goal is to have a single point of entry for each of these project facets.
Lobid application modules
Lobid application modules share this general goal of a focussed module that does one thing. They should usually not require a Metafacture transformation (which suggests an additional data module), but may use an app-specific Elasticsearch index. They implement their HTTP data communication, URL routes, and HTML/JS/CSS rendering with the Playframework.